// 깊은 복사 메서드
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
// 2. Arrays.copyOf() 메서드
int[] a = { 1, 2, 3, 4 };
int[] b = Arrays.copyOf(a, a.length); // 배열과 함께 length값도 같이 넣어줍니다.
}
}
Collection
List
리스트는 크기가 가변적으로 늘어나는 동적배열이다.
ArrayList<Integer> intList = new ArrayList<Integer>(); // 선언과 동시에 생성 크기 지정x
intList.add(99);
intList.add(50);
intList.add(12); // 값이 추가되면서 크기가 늘어난다.
System.out.println(intList.get(1));
intList.set(1, 77); // 값을 수정
System.out.println(intList.get(1));
ArrayList<Integer> intList = new ArrayList<Integer>(); // 선언과 동시에 생성
intList.add(99);
intList.add(50);
intList.add(12);
System.out.println(intList.get(0));
intList.remove(0);
System.out.println(intList.get(0));
결과 : 99
50 // remove로 값을 제거하면 뒤에 있던 값들이 앞으로 땡겨진다.
Stack
값을 수직으로 쌓아놓고 넣었다가 빼서 조회하는 형식으로 데이터를 관리하는 자료형
LIFO “나중에 들어간 것이 가장 먼저 나온다(Last-In-First-out)”
Stack<Integer> intStack = new Stack<>();
intStack.push(29);
intStack.push(7);
intStack.push(1004); // 값을 넣어줌
while (!intStack.isEmpty()){
System.out.println(intStack.pop()); // 맨 위에 값을 꺼낸다.
}
// 결과 :
1004
7
29
Set
순서가 없고 자료의 중복을 허용하지 않는 집합으로 생성자가 없어 생성자가 존재하는 HashSet 클래스를 이용해서 생성한다.
선언 : Set<Integer> intSet
생성 : new HashSet<Integer>()
추가 : intSet.add({추가할 값})
조회 : intSet.get({조회 할 순번})
삭제 : intSet.remove({삭제할 값})
포함확인 : intSet.contains({포함확인 할 값}) - 해당값이 포함되어 있는지 boolean 값으로 응답
Map
key-value 구조로 key값은 중복을 허용하지 않는다.
선언 : Map<String, Integer> intMap
생성 : new HashMap<>()
추가 : intMap.put({추가할 Key값},{추가할 Value값})
조회 : intMap.get({조회할 Key값})
전체 key 조회 : intMap.keySet() - Map의 모든 Key를 모아서 Set 자료형으로 리턴
전체 value 조회 : intMap.values() - Map의 모든 Value를 모아 Set 자료형으로 리턴
삭제 : intMap.remove({삭제할 Key값})
연습
자료구조 요리 레시피 메모장 만들기
입력값
저장할 자료구조명을 입력합니다. (List / Set / Map)
내가 좋아하는 요리 제목을 먼저 입력합니다.
이어서 내가 좋아하는 요리 레시피를 한 문장씩 입력합니다.
입력을 마쳤으면 마지막에 “끝” 문자를 입력합니다.
출력값
입력이 종료되면 저장한 자료구조 이름과 요리 제목을 괄호로 감싸서 먼저 출력해줍니다.
이어서, 입력한 모든 문장 앞에 번호를 붙여서 입력 순서에 맞게 모두 출력해줍니다.
내가 작성한 코드 일부
switch (type) {
case "List" :
boolean flag = true;
ArrayList<String> recipeArr = new ArrayList<>();
while (flag) {
String recipe = sc.nextLine();
recipeArr.add(recipe);
if(recipe.equals("끝")) {
flag = false;
}
}
System.out.println("[ " + type + "으로 저장된 " + title + " ]");
for(String item : recipeArr) {
System.out.println(item);
}
break;
정답 코드 일부
switch (collectionName) {
case "List":
ArrayList<String> strList = new ArrayList<>();
while (true) {
// 한줄씩 입력받아서 strList 에 저장
String text = sc.next();
if (Objects.equals(text, "끝")) {
break;
}
strList.add(text);
}
title = "[ List로 저장된 " + title + " ]"; // [ 제목 ]
System.out.println(title);
// strList 한줄씩 출력
for (int i = 0; i < strList.size(); i++) {
int number = i + 1;
System.out.println(number + ". " + strList.get(i));
}
break;
알게 된 점
"끝"을 입력받았을 때 boolean 변수를 false로 바꿔서 while문을 빠져나왔는데 정답코드를 보니 그냥 간단하게 break를 쓰면 됐었다. 아직 break가 익숙지 않아서 이런 차이가 생긴 것 같다.
처음에 레시피를 next()로 받았더니 레시피를 한 줄 단위가 아닌 단어로 받아와서 nextLine()으로 수정했다. 공백을 포함한 한 줄을 온전히 받으려면 nextLine 메서드를 써야겠다.
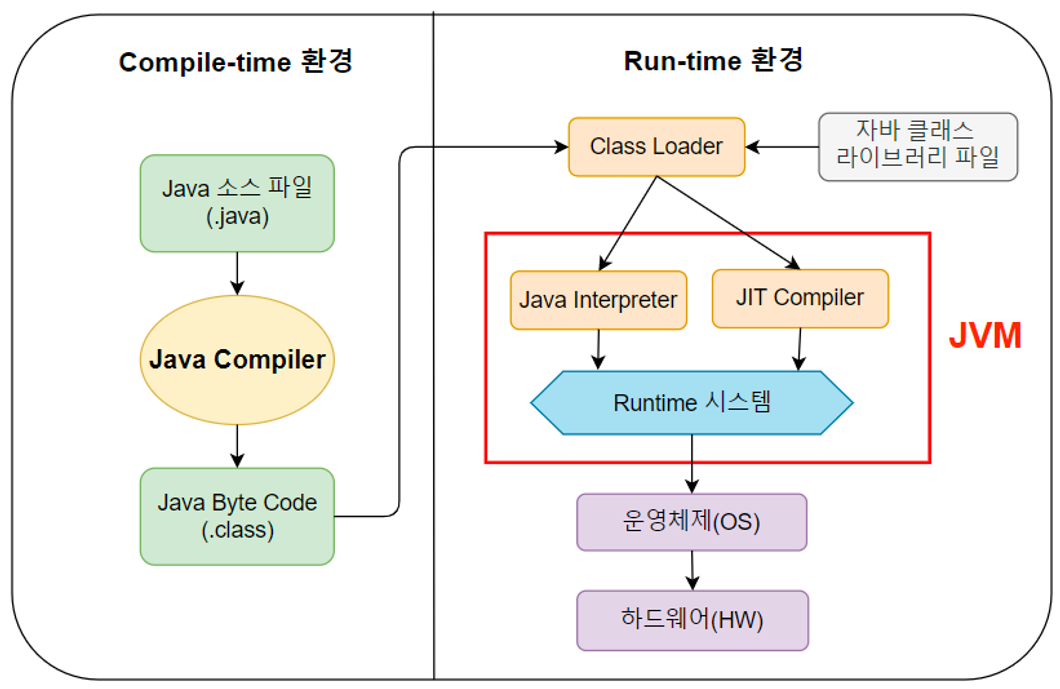
Java 코드(.java 파일)를 운영체제가 읽을 수 있는 바이트 코드(.class 파일)로 변환
인터프리터
운영체제가 읽은 바이트 코드를 기계어로 번역
JIT 컴파일러
인터프리터의 효율을 높여주는 서포터 해석기
클래스 로더
JVM으로 바이트 코드를 불러와서 메모리에 저장
가비지 컬렉터
메모리 영역에서 안쓰는 데이터를 주기적으로 흡수해가는 청소기
JRE의 기능
Java Runtime Environment 자바 실행 환경
.class 파일만 실행 가능
JDK의 기능
JRE(JVM)의 기능 : .class 파일 실행
Java Compiler(javac) 기능 : .java 파일을 .class 파일로 컴파일
JDB 기능 : 디버깅
기본형 변수
모두 소문자로 시작된다
비객체 타입이므로 null 값을 가질 수 없다. (기본값이 정해져 있음)
변수의 선언과 동시에 메모리 생성
모든 값 타입은 메모리의 스택(stack)에 저장
저장공간에 실제 자료 값을 가진다.
참조형 변수
기본형 과는 달리 실제 값이 저장되지 않고, 자료가 저장된 공간의 주소를 저장한다.
즉, 실제 값은 다른 곳에 있으며 값이 있는 주소를 가지고 있어서 나중에 그 주소를 참조해서 값을 가져온다.
메모리의 힙(heap)에 실제 값을 저장하고, 그 참조값(주소값)을 갖는 변수는 스택에 저장
참조형 변수는 null로 초기화 시킬 수 있다.
String, 객체, 배열, 리스트 등등
Stack 영역 vs Heap 영역
Stack의 경우에는 정적으로 할당된 메모리 영역
크기가 정해져 있는 변수를 저장
크기가 정해져 있는 참조형 변수의 주소 값도 저장
Heap의 경우에는 동적으로 할당된 메모리 영역
크기가 계속 늘어날 수 있는 참조형 변수의 원본을 저장
ASCII 코드 형변환
입력한 정수를 문자로 바꿔서 출력하는 메서드
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int asciiNumber = sc.nextInt();
char ch = (char)asciiNumber;
System.out.println(ch); // 입력한 글자를 출력합니다.
}
}
입력한 문자의 제일 첫 글자를 숫자로 출력하는 메서드
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int letter = sc.nextLine().charAt(0); // charAt(0) :첫번쨰 문자를 받아온다.
int asciiNumber = (int)letter;
System.out.println(asciiNumber); // 입력한 글자를 출력합니다.
}
}
팀소개 페이지 만들기 프로젝트를 하면서 HTTP 주요 메서드에 대해 공부했다. 나는 프로젝트에서 상세 보기 페이지와 프로필 수정 기능을 맡았는데 POST 메서드로도 리소스를 수정할 수 있는데 왜 PUT 메서드가 따로 있는지 의문이 들었다. 그래서 프로필 수정 기능을 먼저 익숙한 POST 메서드로 구현해 보고 PUT 메서드를 이용해서 다시 짜봤다. 그런데 막상 실행시켜보니 겉보기엔 두 메서드에 별 다른 점이 없어 보여 어떤 차이점이 있는지 알아봤다.
POST 메서드와 PUT 메서드의 차이점은 멱등성에 있다는데 동일한 요청을 한번 보내는 것과 여러번 연속으로 보내는 것이 같은 효과를 가지고, 서버의 상태도 동일하게 남을 때 해당 HTTP 메서드가 멱등성을 가진다고 한다.
POST
POST는 서버로 데이터를 전송하여 새로운 자원을 생성하는 역할을 한다. 따라서 요청을 여러 번 보내는 경우 매번 새로운 자원이 생겨나는 것이며, 이는서버의 상태가 변경되는 것을 의미한다. 그러므로 POST 메서드는 멱등성을 가지지 않는다.
PUT
PUT 메서드는 대상 리소스를 덮어씌워 변경하거나, 대상 리소스가 없다면 새로 추가한다. 만일 대상 리소스가 없다면 PUT이 POST와 같은 동작을 하게 되는데, POST는 매번 새로운 자원을 만드는 반면, PUT은 해당 자원이 이미 있다면 데이터만 덮어쓴다. 따라서 요청을 한번하든 여러 번 하든 결국 서버의 상태는 같아지니, PUT은 멱등하다.
사실 멱등성이란 말이 낯설어서 그런지 아직 무슨 뜻인지 잘 와닿진 않지만 앞으로 계속 쓰다 보면 언젠간 '아 이게 이런 뜻이구나' 알게 될 날이 올 것 같다.
발표할 때 각자 자신의 각오를 준비하라고 하셔서 좀 부담스럽기도 하고 어색했는데 막상 끝나고 보니 발표 내용보다 각오가 더 기억에 남는다. 나와 같은 고민과 걱정을 가지신 분들이 많았어서 다른 분들의 각오를 듣는 게 생각보다 큰 위로와 용기가 됐다. '아는 게 없는데 잘 따라갈 수 있을까?', '내가 팀에서 한 사람의 몫을 제대로 할 수 있을까?'와 같은 고민들 말이다. 혼자서는 자신 없어도 팀을 이뤄 협동하면 어떻게든 해낼 수 있을 거란 생각이 들었다.
그리고 팀 프로젝트를 할 때 용건만 간단히 말하는 게 가장 효율적인 방법이라 생각했는데 다른 팀들을 보니 팀의 분위기를 재밌게 만드는 것 또한 아주 중요하다는 것을 깨달았다. 분위기가 어느정도 편하고 즐거워야 의견을 쉽게 내고 그래야 원활한 의사통이 이루어지는 것 같다. 막히는 부분이 생기면 검색을 통해 혼자 해결하려고 했는데 다음부터는 좀 더 팀원들에게 질문도 하고 적극적으로 의사소통해보고 싶다.